Detect and resolve Major Incidents with AI
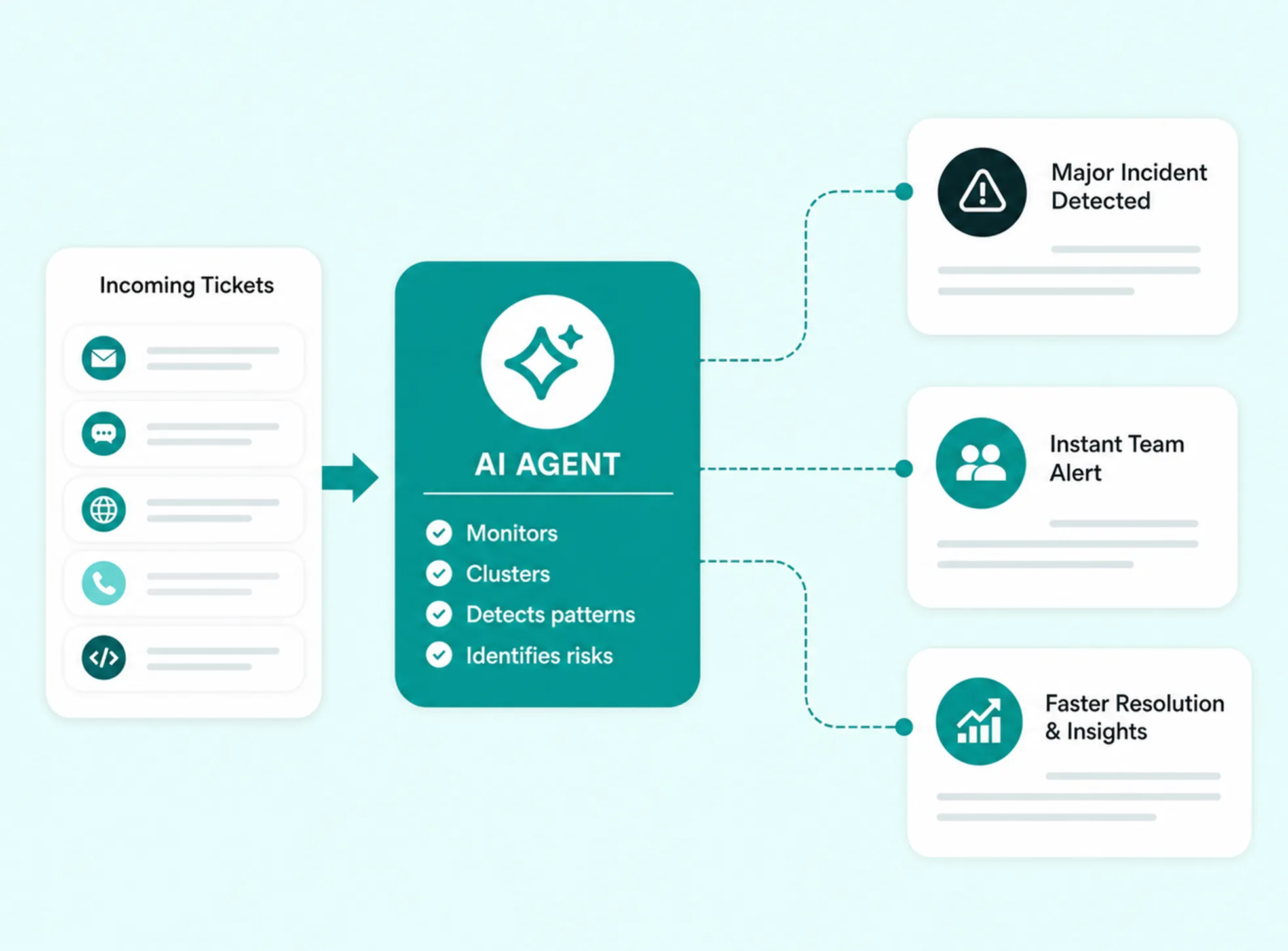
An AI agent that monitors your incoming ticket stream, clusters related incidents in real time and alerts your team the moment a pattern signals a Major Incident or recurring problem.
Control incidents before they become outages

Groups related incidents into live clusters as they arrive in real time
Flags fast-growing clusters for immediate Major Incident response
Surfaces slow-burning recurring patterns as Problem candidates
Auto-generates incident records with linked tickets and suggested priority
Pre-populates root cause analysis templates ready for human review

Surfaces proven workarounds the moment a Problem or MI is reported
Notifies agents instantly when a Major Incident touches their tickets
Centralized view of active clusters, candidates, and recent actions

Prevent critical outages with AI-powered major incident management

The AI watches every incoming ticket and groups semantically similar incidents into clusters in real time. When a cluster grows fast enough to signal an outage, your team is alerted before the impact spreads
Rezolve.ai reads cluster shape and growth speed to distinguish fast-moving outages from slow-burning recurring Problems, so each gets the right response at the right pace.


When a Major Incident is declared, Rezolve.ai automatically generates a draft record with linked tickets, suggested priority, and a pre-filled RCA template, so your team starts the response ASAP.
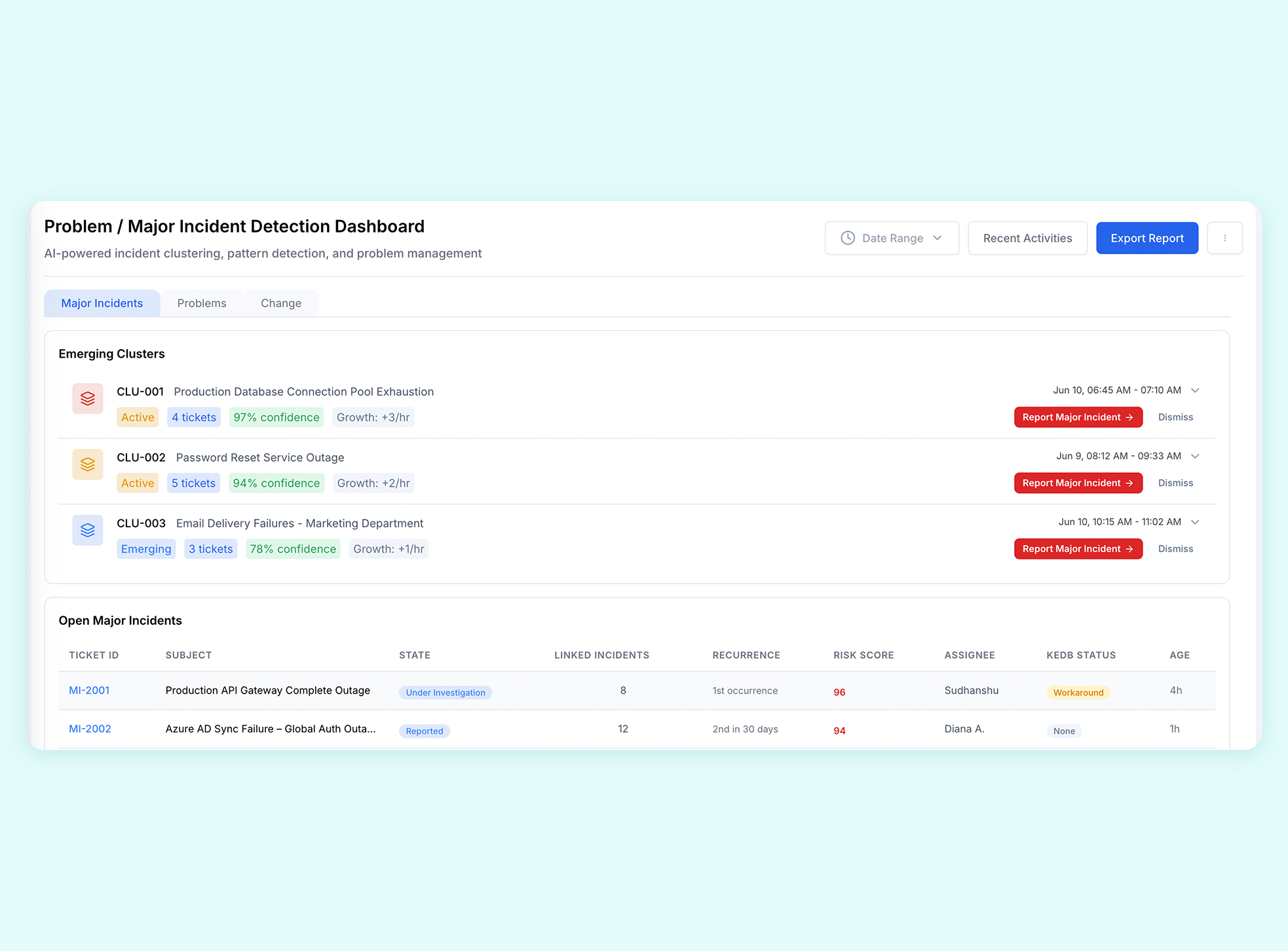
The Problem and Major Incident Dashboard gives Problem Managers a complete picture of active clusters, problem candidates, and recent actions with filters to cut through the noise fast.
Learn, Watch & Explore
Videos, blogs, and webinars to help you discover what’s next in Agentic AI.








FAQs
Major Incident Management in Rezolve.ai is an Agentic AI capability that monitors your incoming ticket stream, clusters semantically similar incidents, and alerts the right people in real time when a pattern signals a Major Incident or recurring Problem. It covers detection, alerting, record drafting, and known error matching, all in one connected workflow.
The AI reads the shape and growth rate of each ticket cluster. Fast-growing clusters that signal a widespread outage surface as Major Incident candidates requiring attention within minutes. Slower-burning clusters that reveal a repeating pattern surface as Problem candidates for longer-term investigation. Both go through a human review step before being officially declared.
Service desk agents whose tickets are linked to the active cluster receive a broadcast popup listing impacted tickets and a direct link to the MI record. Inline banners on individual tickets also alert agents that their ticket is part of a growing cluster. Problem Managers and MI Managers access the full picture through the dedicated dashboard and draft record drawer.
Each AI-drafted record includes linked incident tickets, a suggested priority level, and a pre-filled RCA template populated with available context. The draft is presented to a human reviewer who can edit and publish it. Known Error Database matches are also surfaced at this stage as suggested workarounds or solutions.
Yes. Tenant admins can configure similarity scoring thresholds, cluster size and growth rate parameters, and RCA template content from the configuration page. Detection sensitivity can be tuned to match the scale and pace of your specific IT environment without any custom development.