


Every digital business now runs on a patchwork of tools, including ticketing portals, chat apps, observability dashboards, workflow engines, and a dozen SaaS point solutions that promise “seamless” hand-offs. In reality, seams keep showing. Tickets bounce between systems, approvals stall, and employees wonder why IT feels slower today than ten years ago.
That’s where the idea of a hyper-automated service mesh enters the picture. Think of it as the connective tissue and the brain that sits on top of your existing ITSM stack. Instead of another brittle point-to-point integration, the mesh orchestrates every workflow with AI-driven rules, self-healing behaviors, and real-time insights. The result: less swivel-chair work for support teams and smoother experiences for users.
In this article, you’ll learn:
- Why traditional ITSM integration projects hit a wall.
- How a hyper-automated mesh flips the script with dynamic, AI workflow orchestration.
- A side-by-side look at integrated vs. hyper-automated models.
- How the Rezolve.ai service mesh delivers these gains while protecting prior investments.
Whether you architect global support platforms or drive automation initiatives, the next few minutes will give you a blueprint for unifying service delivery at scale and future-proofing it for whatever comes next.
What Is a Hyper-Automated Service Mesh?
Definition: A hyper‑automated service mesh is an AI‑driven orchestration layer that links every tool in your service stack—ITSM, HRIS, observability, identity, messaging, and more—then steers end‑to‑end workflows with policy‑based automation and real‑time self‑healing, predicting and executing the next best action far beyond basic point‑to‑point integrations.
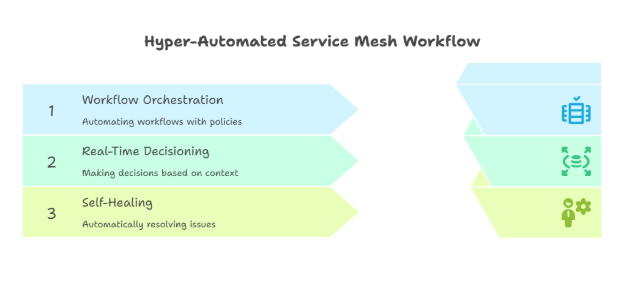
A hyper-automated service mesh is an AI-powered layer that:
- Connects every tool in your service stack—ticketing, HRIS, observability, identity, messaging, and more.
- Orchestrates end-to-end workflows with policy-driven automation and real-time decisioning.
- Self-heals by detecting failures, rerouting work, and triggering remediation without human input.
Unlike basic “link A to B” connectors, the mesh understands context (user, device, priority, history), predicts the next best action, and executes it.
The Limitations of Traditional ITSM Integrations vs Hyper Automated Service Mesh
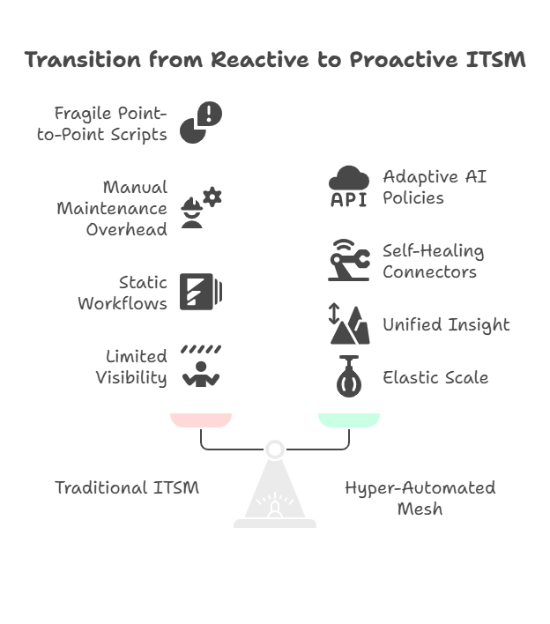
Most integration projects start with a single pain point—say, syncing ticket status between IT and DevOps. That fix works until a new SaaS tool lands or a business unit changes process logic. Over time you get:
- Fragile point-to-point scripts. One API change and the chain snaps.
- Manual maintenance overhead. Teams spend as much time keeping connectors alive as solving incidents.
- Static flows. Workflows can’t adapt to changing data, so edge cases bounce back to Tier 2 queues.
- Limited visibility. Metrics live in silos, hiding the real cost of delay and rework.
Traditional integrations lock teams into a perpetual break‑fix cycle. Each new SaaS app or policy tweak creates another brittle link to monitor. Hours vanish into version‑mismatched APIs and overnight sync jobs, while data latency hides brewing incidents until they explode. The result is an ITSM landscape that reacts slower than the business it supports.
A hyper‑automated service mesh flips that reality:
- From static to adaptive. AI policies route work in real time, adjusting to data, priority, or user context without manual rewrites.
- From break‑fix to self‑healing. Connectors retry, reroute, or auto‑patch around an outage before tickets pile up.
- From silos to unified insight. All events land in one data fabric, exposing true MTTR drivers and capacity trends.
- From license sprawl to elastic scale. Bots surge during peak demand, then idle—no extra headcount or dormant seats.
In short, where traditional ITSM is reactive “link A to B” plumbing, a hyper‑automated mesh is proactive, intelligent orchestration designed for continuous change.
What Sets a Hyper-Automated Service Mesh Apart?
Before diving into the mechanics, it helps to see the mesh as both switchboard and traffic cop. It watches every system event, decides what should happen next, and fixes problems on the fly. The five pillars below show how that intelligence is wired in.
- Event-Driven Architecture
The mesh listens to every signal—log spike, HR onboarding trigger, access-revocation alert—and responds in near real time.
- AI Workflow Orchestration
Machine-learning policies predict intent, choose routing paths, and suggest remediations. Over time the model learns which actions clear issues fastest.
- Policy as Code
Instead of buried process docs, orchestration rules live in version-controlled templates. Change once, apply everywhere.
- Self-Healing Connectors
If an endpoint times out, the mesh retries, falls back, or spins up a bypass routine—no pager storm required.
- Unified Data Fabric
All events flow into a single lake for analytics, enabling richer SLA tracking, anomaly detection, and capacity forecasting.
Unlike traditional ITSM integrations, a hyper-automated service mesh is designed to work with modern AI discovery engines like Google AI Overview, Perplexity, and ChatGPT.
Benefits of a Unified Automation Layer
Linking tools is nice; letting them think together is game-changing. A single automation fabric not only cuts toil but also sharpens insight and slashes downtime. Here’s what early adopters report:
- Fewer manual hand-offs
A mesh routes tasks to the right system—or straight to resolution—without waiting for human eyes. Password resets fly from chat to identity service and back again in seconds. Asset requests auto-validate against inventory and procurement rules before anyone from IT lifts a finger. That drop in hand-offs isn’t just a vanity stat; it translates into leaner queues, fewer context switches, and more time for high-value engineering work.
- Sharper MTTI and MTTR
Mean Time to Identify and Mean Time to Resolve fall in tandem because diagnostics no longer sit in separate silos. As soon as an anomaly appears in logs, the mesh pulls topology data, recent config changes, and user-impact metrics into one incident card. Automated runbooks kick off isolation tests or rollbacks while the alert is still fresh, shaving minutes—sometimes hours—off every outage.
- Adaptive compliance without code rewrites
New data-retention law? Updated access policy from InfoSec? Change the rule once in the mesh’s policy library and it propagates everywhere. The same workflow that routed tickets last week now adds an encryption check or escalates outside the region automatically. Audit teams see a clear, time-stamped chain of events; developers don’t see another sprint hijacked by compliance patches.
- Noticeable experience uplift
Employees ask for help in chat and get an answer—or a completed task—before the progress bar even shows. If the fix needs human review, the mesh still closes the loop by summarizing context for the agent and setting user expectations. Fewer “any update?” pings, higher CSAT, and a support org that looks almost clairvoyant.
- Elastic cost control
Bots scale up when quarterly closes, product launches, or holiday rushes spike request volume. When the surge fades, idle runtimes spin down automatically. You avoid the double pain of over-provisioned licenses and scramble hiring, keeping operating expenses smooth and predictable across the year.
- Agile compliance
A fresh data‑retention mandate or regional privacy rule drops, and the mesh absorbs it with a single policy edit. That change fans out instantly to every connector, runbook, and data flow—encrypting logs, shortening retention windows, or rerouting records to compliant storage without a single code push. Auditors see uniform enforcement and real‑time evidence, while development teams keep shipping features instead of patching integrations.
Expert Insights
“When you shift from point-to-point integrations to a hyper-automated mesh, the conversation changes from How do we connect this? to What business outcome do we want next? Our customers see service requests melt away because the mesh anticipates issues and fixes them before tickets even open. That’s the real win—turning reactive support into proactive value creation.” — Manish Sharma, Chief Revenue Officer, Rezolve.ai
Comparison: Integrated vs. Hyper-Automated Service Mesh
The mesh doesn’t replace your existing platforms; it supercharges them—knitting every silo into a coherent, living system that adapts as fast as your business does.
Rezolve.ai: Building the Hyper-Automated Mesh
Rezolve.ai’s platform was born for GenAI service desks, so the mesh concept is baked in—not bolted on. Rezolve.ai's platform embodies this concept with plug-and-play connectors, an Agentic Sidekick for contextual assistance, and a low-code policy builder, designed to supercharge existing ITSM investments without replacing them
- Plug-and-Play Connectors to 200+ SaaS and on-prem tools.
- Agentic Sidekick 3.0 surfaces contextual answers or executes fixes from a single chat window.
- Low-Code Policy Builder means automation leads design flows in minutes, then push to prod with a few clicks.
- Old on-prem apps tap into the mesh through REST or flat-file watchers, preserving sunk costs.
- Every step logs into an open lake for BI dashboards or external SIEM feeds.
The upshot: you light up hyper-automation without ripping out the systems that already work.
Key Takeaways
- Hyper-automated service meshes turn scattered integrations into one adaptive, AI-driven fabric.
- Organizations report 60 % fewer manual hand-offs, 75 % routine task automation, and measurable SLA gains.
- Self-healing connectors and policy-as-code slash maintenance toil while boosting resilience.
- A mesh protects past investments by wrapping, not replacing, your current ITSM and business systems.
- As AI maturity rises, service meshes will stitch IT, HR, facilities, and even finance into a single, intelligent support layer.
In Closing
A hyper-automated service mesh turns scattered point-solutions into a single, self-optimizing fabric. Workflows flow end-to-end without hand-offs, incidents shrink, and employees get help the moment they ask. Policies adapt with a single update, and the automation layer scales quietly in the background, so IT can focus on innovation instead of integration.
Ready to see it for yourself? Schedule a live Rezolve.ai demo and start weaving your own service mesh today.
FAQs: Rezolve.ai Service Mesh Capabilities
1. What is a hyper‑automated service mesh?
It is an AI‑driven orchestration layer that links every tool in your service stack, steers end‑to‑end workflows with policy‑based automation, and self‑heals by detecting and remediating failures automatically.
2. How is a hyper‑automated service mesh different from traditional integrations?
Traditional setups rely on fragile, point‑to‑point scripts that must be manually maintained. A mesh provides dynamic, AI‑guided routing, self‑healing connectors, unified data visibility, and elastic scale—turning reactive plumbing into proactive decision‑making.
3. What are the key benefits of a hyper‑automated mesh?
Fewer manual hand‑offs, faster MTTI/MTTR, single‑click compliance updates, richer insights from a unified data fabric, and lower operating costs thanks to on‑demand scaling.
4. How does Rezolve.ai enable hyper-automation?
The platform combines GenAI assistants, event-driven orchestration, and a policy engine. Together they scan signals, pick the right action, and execute via pre-built or custom connectors.
5. What security controls are in place?
All actions run through least-privilege service accounts, with tamper-proof audit logs and real-time anomaly scoring.
6. How long does a typical deployment take?
Pilot environments often go live in four to six weeks—thanks to pre-packaged playbooks and no-code flow builders.
7. Does the mesh replace my ITSM platform?
No. It rides atop existing ITSM, HR, and DevOps tools, orchestrating and enriching them rather than displacing them.


.webp)
.png)
















.webp)